Visual-Qwen & Sludge-Qwen:
Augmenting Multimodal Deep Learning with Attention Mechanisms to Recognize ”Sludge Content” from Short Form Videos
Abstract
The proliferation of ”sludge” content in short-form videos featuring multiple, unrelated clips playing simultaneously presents a significant challenge to conventional content moderation systems on platforms like TikTok and YouTube Shorts. This format is engineered to manipulate recommendation algorithms and circumvent moderation by creating deliberate audiovisual mismatches, a tactic that unimodal analysis tools fail to reliably detect. This research addresses this gap by developing and evaluating Visual-Qwen, a novel multimodal deep learning architecture augmented with attention mechanisms for the automated recognition of sludge videos.
The proposed model integrates a frozen CLIP ViT-L/14 vision encoder and a Whisper V3 Turbo audio transcription module to extract visual and textual features, respectively. A lightweight Query-Former (Q-Former) acts as a cross-modal attention fusion mechanism, distilling these heterogeneous inputs into a compact set of learned embeddings. These fused features are then projected into a frozen Qwen3-4B large language model, which generates a final classification and a human-readable explanation. To ensure robust and generalizable performance, the model was trained on a custom-built dataset of 2,000 sludge and non-sludge videos, which was ethically sourced, annotated via a human-in-the-loop pipeline, and validated by industry experts against ISO/IEC 25012 data quality standards.
Evaluated on a held-out test set, the Visual-Qwen model achieved 93.50% accuracy, 91.09% precision, 95.83% recall, and a 93.40% F1-score. Furthermore, evaluations conducted with content creators, content moderators, and machine learning experts confirmed the system"s high utility and trustworthiness, scoring favorably on assessments based on the Technology Acceptance Model (TAM) and ISO/IEC TR 24028 guidelines. This study demonstrates that an attention-augmented multimodal approach can effectively identify complex and evasive content formats, offering a significant contribution to developing more sophisticated and resilient automated content moderation systems.
Model
Visual-Qwen consists of a frozen CLIP ViT-L/14 vision encoder and a Whisper V3 Turbo audio transcription module, a lightweight Query-Former (Q-Former), and a frozen Qwen3-4B large language model.
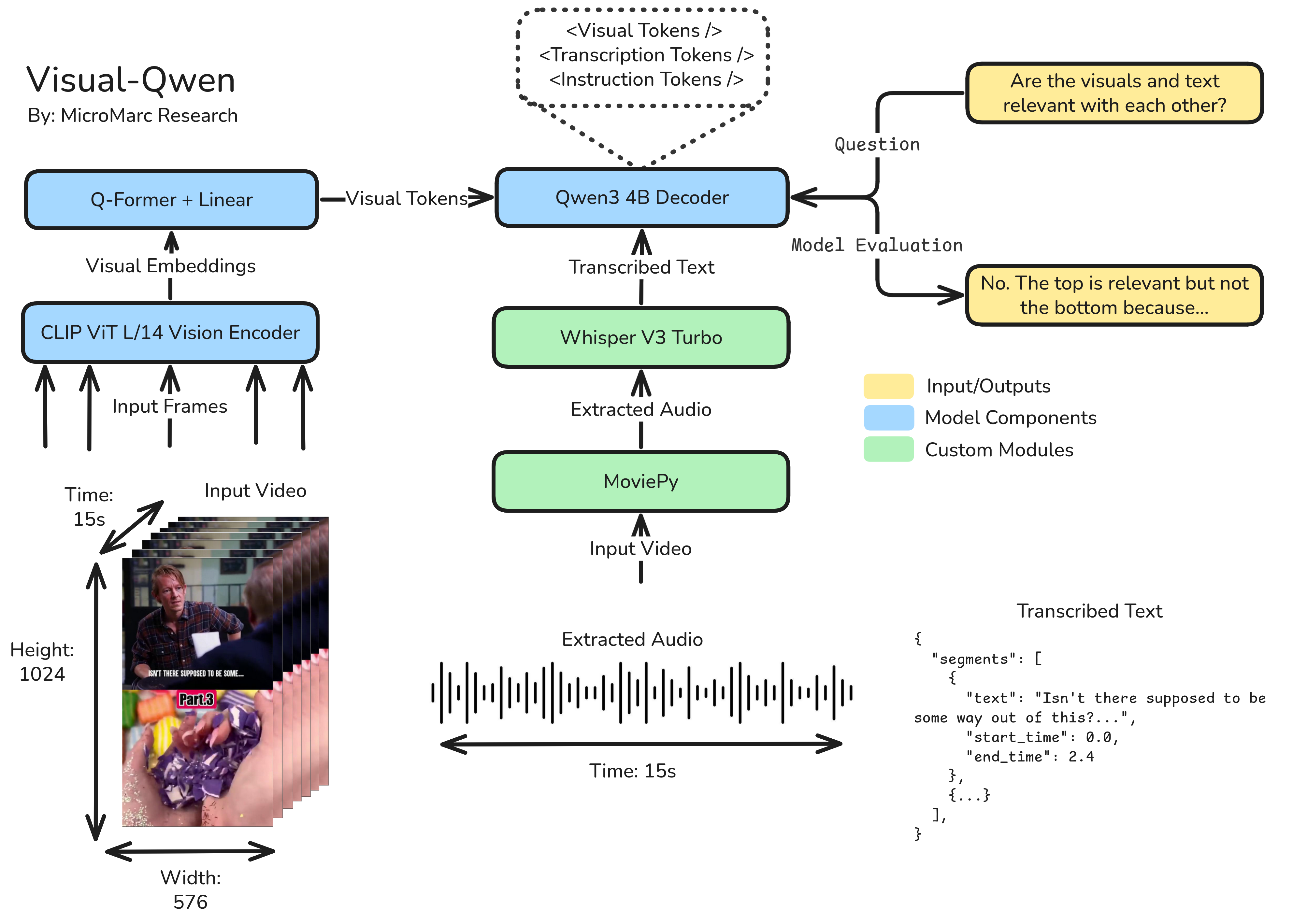
Dataset
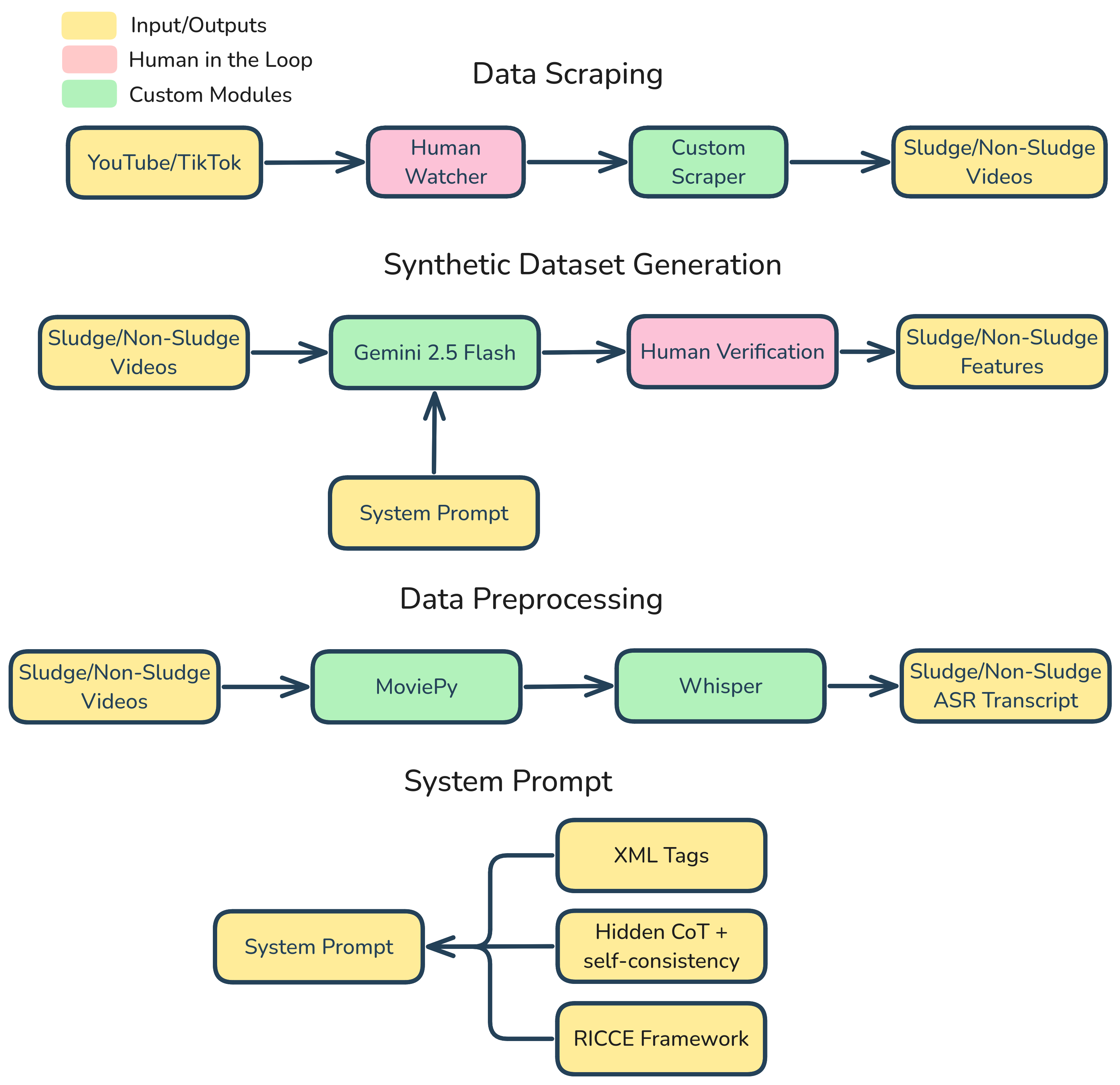
The dataset consist of 2000*3 (or 6000) rows of paired multimodal data (video, audio, and text) and is ethically sourced, abiding by the YouTube Researcher Program. It was annotated via a human-in-the-loop pipeline, and validated by Data Scientists against ISO/IEC 25012 data quality standards.
Training
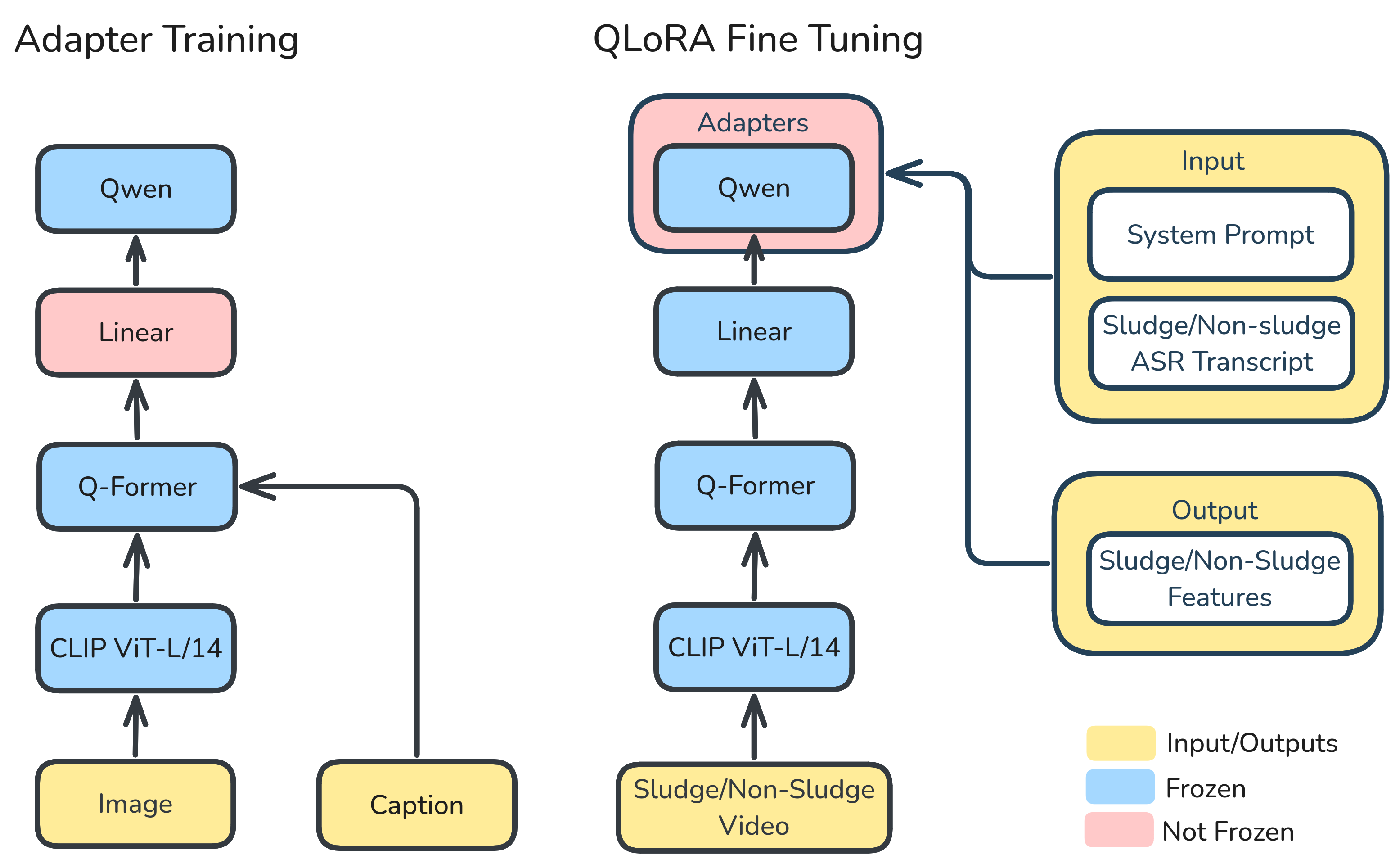
The model was trained on Google Cloud"s TPU v4-64 pods granted by the TPU Research Cloud with MiniGPT"s 5M row dataset and our 2k row fine-tuning dataset, ingested via Cloud Storage FUSE.
Acknowledgement
This website is adapted from MiniGPT-4, licensed under a BSD-3-Clause License.